Pandas經常用來處理二次元的資料,也就是同時擁有行(Column)跟列(Row)的資料。常見的資料檔案有我們的cvs檔,也就是我們的excel檔。這篇文章主要會介紹如何使用Pandas中的index, columns, to_numpy, loc, iloc等用法。
取得DataFrame資料(index, columns, to_numpy)
DataFrame型式的變數df主要有三個較常使用的部分,分別可以透過下面的方式取得。
- df.index : 取得index
- df.columns() : 取得列的名字
- df.to_numpy() : 整體數據轉換成narray數據
另外,只要用下面的方式生成DataFrame的話可以同時指定index以及columns名稱。
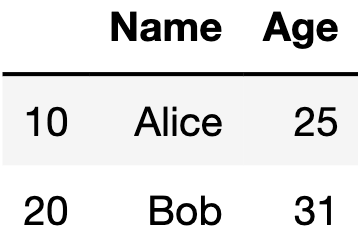
下面的代碼已經將index指定為[10, 20],columns指定為[‘Name’, ‘Age’]。
df = pd.DataFrame(
[["Alice", 25], ["Bob", 31]],
index=[10, 20],
columns=["Name", "Age"],
)
df透過Jupyter notebook執行後會有下面的結果。
接著我們試著透過df.index, df.columns, df.to_numpy()來取得DataFrame中的各項索引。
index = df.index
columns = df.columns
array = df.to_numpy()輸出
Int64Index([10, 20], dtype='int64')
Index(['Name', 'Age'], dtype='object')
[['Alice' 25]
['Bob' 31]]
從上面我們可以得知,df的index我們可以透過df.index來取得。輸出結果的Int64Index是pandas.index的數據。
另外,df的各列名稱可以透過df.columns來取得,而整體數據的部分可以透過to_numpy來取的,不過這邊要注意的是取得的數據是二次元的數據。
Index及Columns的名稱變更
上面我們使用的範例代碼是已經將index及columns指定的代碼,這部分我們來學習如何更改index及columns的名稱。
df = pd.DataFrame(
[["Alice", 25], ["Bob", 31]],
)
df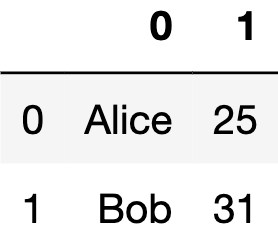
這邊我們可以看到,index跟columns的名稱分別都是0與1。我們就來嘗試將index更改為[10, 20],columns更改為[‘Name’, ‘Age’]
df.index = [10, 20]
df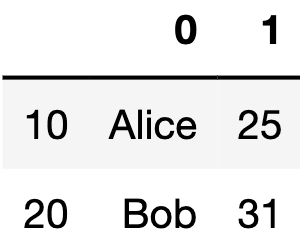
df.columns = ["Name", "Age"]
df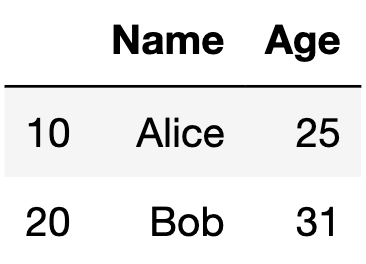
df.loc
在DataFrame的數據中,我們可以透過下面的方式取的特定的行列的數據。
- df.loc[行名] :取得特定的行的數據
- df.loc[:, 列名] : 取得特定的列的數據
- df.loc[行名, 列名] :取得特定行列的數據
以剛剛上面的範例代碼為例。
df = pd.DataFrame(
[["Alice", 25], ["Bob", 31]],
index=[10, 20],
columns=["Name", "Age"],
)
dfdf.loc[20]
df.loc[:, 'Name']結果分別會像下面這樣。

我們也來嘗試指定特定的行列的數據並且將它變更試試看。
df.loc[10, 'Age'] = 88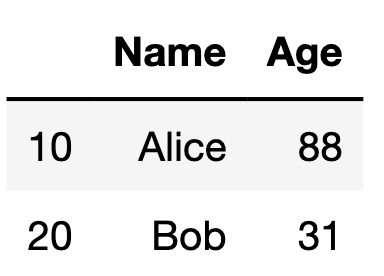
在這邊要跟大家提醒的是,雖然在指定特定的行列時我們可以透過下面的方式。
df.'Age'
df['Age']但筆者這邊比較推薦的是使用df.loc[:, ‘Age’]這個用法。
原因是如果當行列同時有共同名稱’Age’時的話,使用上面的df.’Age’, df[‘Age]等寫法就會出現Error。由於我們在處理資料時通常無法完全掌握各個行列的名稱,因次推薦使用df.loc這個方式來取得數據。
df.iloc
最後要介紹的是df.iloc的用法,這邊跟剛剛上面的df.loc概念一樣,只是剛剛df.loc是透過行列的名字來指定數據,但df.iloc是透過號碼來指定數據。
延續剛剛上面的代碼我們可以直接看下面的範例。
print(df.loc[20])
print(df.iloc[1])
我們可以看到會有一模一樣的結果。只是df.iloc是使用號碼來指定數據。
當然也可以同時指定行跟列。
df.iloc[[0, 1], [1]]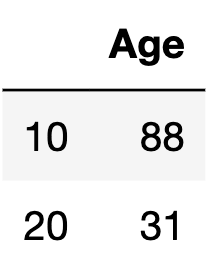
這邊介紹了在使用DataFrame時較常使用到的幾種基本功能,希望大家也可以多練習將來可以使用在實務上。