這篇文章將介紹如何透過Pandas來抽對dataframe中的NaN值做處理。NaN值的處理主要有以下三種方式。
- 將擁有NaN值的行或列抽出
- 將擁有NaN值的行或列去除
- 將NaN值替換成其他數值
我們在這篇文章會用下面的dataframe來做範例。
import pandas as pd
df = pd.read_excel('sample.xlsx')
df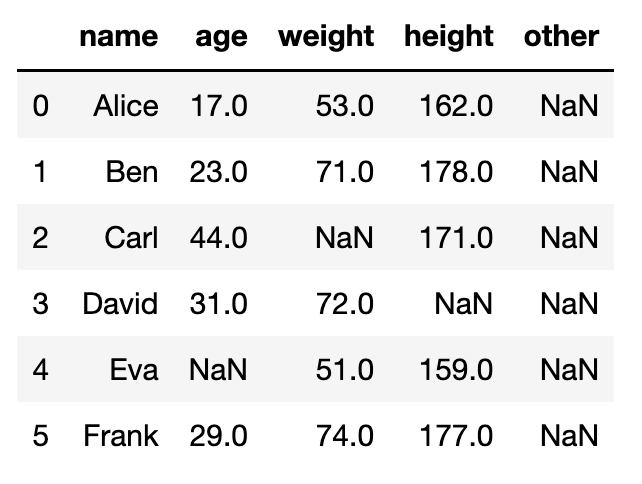
判斷各行列有無NaN值
在pandas.Dataframe中,我們可以透過Series()的isnull()或isna()來判斷各行列中有沒有NaN值。
df.isnull()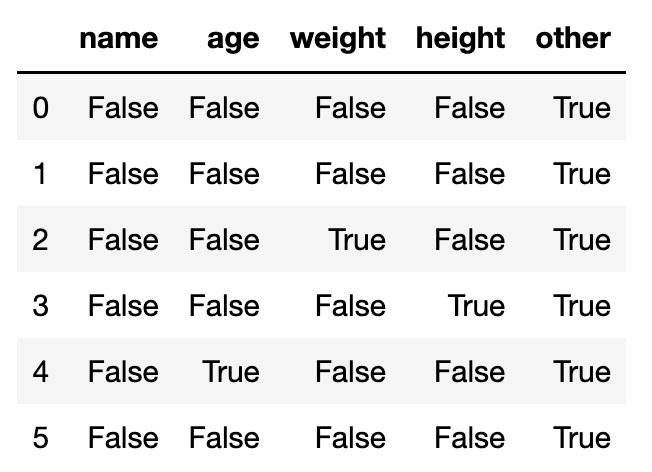
isnull()和isna()的使用方法是一樣的,在這篇文章中會統一使用isnull()(也可以依個人喜好替換成isna())
判斷特定行列有沒有NaN值
在判斷特定行列有沒有NaN值時,也是跟剛剛一樣使用isnull()就可以。可以參考以下範例。
df['age'].isnull()
#0 False
#1 False
#2 False
#3 False
#4 True
#5 False
#Name: age, dtype: bool從上面結果可以知道在第四行的檔案中含有NaN值的檔案。
如果要在整個dataframe中取出有NaN值的數據的話可以透過下面方式。
df[df['height'].isnull()]
如果是對全部都是NaN值的other列作這項處理的話結果會像下面這樣。
df[df['other'].isnull()]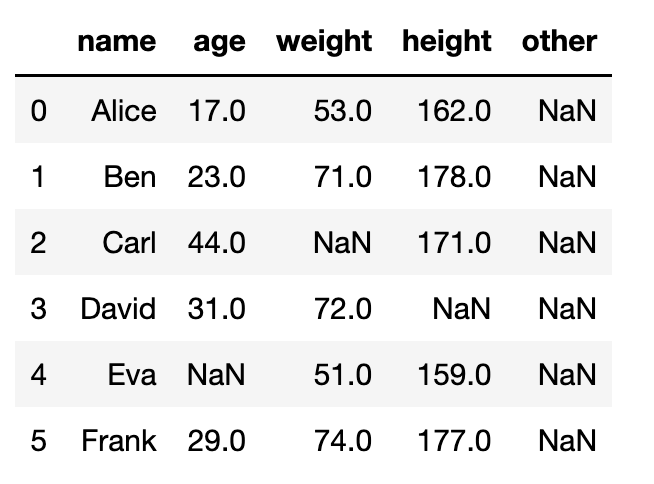
特定出只要有任何一個NaN值的行列
在這邊我們以沒有全部都是NaN值的列的dataframe來做範例。
df2 = df.dropna(how='all', axis=1).dropna(how='all')
df2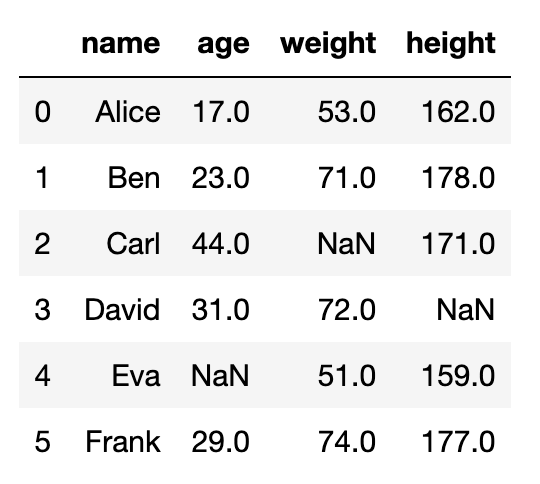
透過any() method我們可以判斷dataframe中有沒有含有True值。另外,設定axis=1是指定成對每行做判定。
df2.isnull().any(axis=1)
#0 False
#1 False
#2 True
#3 True
#4 True
#5 False
#dtype: bool從上述結果可以得知,第2, 3, 4行的數據中含有至少一個NaN值。接著再透過剛剛已經學過的方式來取得擁有NaN值的Dataframe。
df2[df2.isnull().any(axis=1)]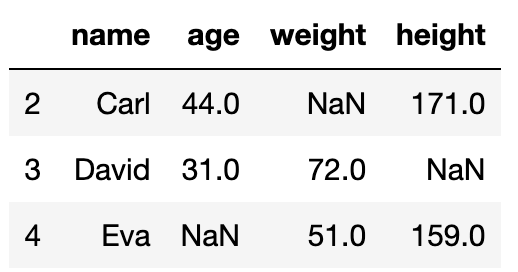
而在對列特定NaN值時也是用相同的方式,在這邊只要將剛剛的any()的axis=1設定成0就可以了(也可以直接不指定axis,default就是0)
df2.isnull().any()
#name False
#age True
#weight True
#height True
#dtype: bool在這邊要注意的是,當要特定出列的NaN值時,因為是要取出整行的數據,因此在這邊要用loc[]來取得數據。代碼會像下面這樣。
df2.loc[:, df2.isnull().any()]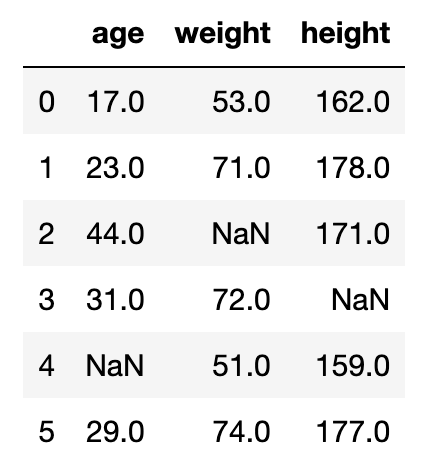

留言